


Сжатие данных
Важнейшей задачей современной информатики является кодирование информации наиболее оптимальным способом.
Равномерное кодирование сообщений сохраняет его статистические свойства: количество символов в исходном сообщении будет равно количеству кодовых слов в закодированном варианте. Это свойство позволяет однозначно декодировать сообщения. Но равномерный код не позволяет уменьшить ресурсные затраты при передаче информации по каналам связи или ее хранении. Значит, для уменьшения информационного объема сообщения необходимы алгоритмы, позволяющие сжимать данные.
Один из подходов к решению проблемы сжатия информации заключался в отказе от одинаковой длины кодовых слов: часто встречающиеся символы кодировать более короткими кодовыми словами по сравнению с реже встречающимися символами.
Принцип неравномерного кода для уменьшения информационного объема сообщения был реализован в азбуке Морзе. Однако, применение кода переменной длины создавало трудности разделения сообщения на отдельные кодовые слова. Эта проблема была решена Морзе путем применения символа-разделителя – паузы.
Префиксные коды
Теоретические исследования К. Шеннона и Р. Фано показали, что можно построить эффективный неравномерный код без использования разделителя. Для этого он должен удовлетворять условию Фано: ни одно кодовое слово не является началом другого кодового слова. Коды, удовлетворяющие условию Фано называются префиксными.
Префиксный код — это код, в котором ни одно кодовое слово не является началом другого кодового слова.
Шеннон и Фано предложили алгоритм построения эффективных сжимающих кодов переменной длины (алгоритм Шеннона – Фано). Однако, в некоторых случаях алгоритм давал неоптимальное решение.
Код Хаффмана
В 1952 году Дэвид Хаффман, ученик Фано, предложил новый алгоритм кодирования и доказал оптимальность своего способа. Улучшение степени сжатия Хаффман достиг за счет кодирования часто встречающихся символов короткими кодами, реже встречающихся – длинными.
Построим код Хаффмана для текста «ОКОЛО КОЛОКОЛА КОЛ»
- Строим список свободных узлов, упорядоченных по убыванию частоты появления буквы.
- Выберем две наименее вероятные буквы и построим для них узел-предок («псевдобуква») с частотой, равной сумме частот узлов-потомков.
- Менее вероятной букве ставим в соответствие 1, более вероятной – 0 (в следующем проходе соблюдаем порядок расстановки 0 и 1).
- Удаляем обе буквы из списка, оставив их узел-предок.
- Повторяем шаги, начиная с пункта 2, до тех пор, пока не останется один узел («метабуква»). Этот узел будет считаться корнем дерева.
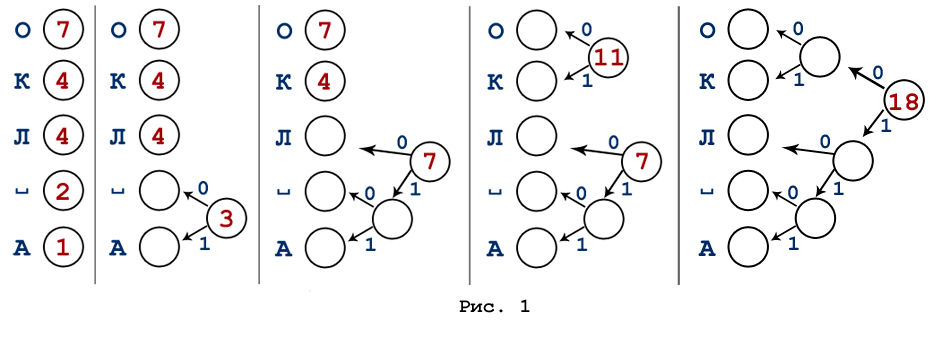
Для получения кода каждого символа движемся от корня дерева до данного символа, выписывая по ходу нули и единицы. В нашем примере символы имеют следующие коды:
- О – 00
- К – 01
- Л – 10
- Пробел – 110
- А - 111