


Кодирование текстовой информации
Представление информации в текстовой форме, сыгравшее огромную роль в развитии человеческой цивилизации, является одним из наиболее универсальных. Обработка текста с помощью компьютера стала доступной уже в 60-е годы прошлого века.
Текстовая информация состоит из набора символов, значит, она изначально дискретна. Поэтому нет необходимости проводить процессы дискретизации и квантования как в случае кодирования графической и звуковой информации.
При кодирование текстовой информации каждому символу ставится в соответствие уникальный десятичный номер в некотором алфавите, представленный в двоичном коде. Такое правило сопоставления кодов и символов алфавита называется кодировкой текста.
Стандарты кодирования.
Первый широко известный стандарт кодирования текста был принят в 1963 году и получил название ASCII (American Standard Code for Information Interchange) – американский стандартный код для обмена информацией). Таблица кодирования содержала символы латинского алфавита, цифры, набор управляющих символов и некоторые знаки препинания.
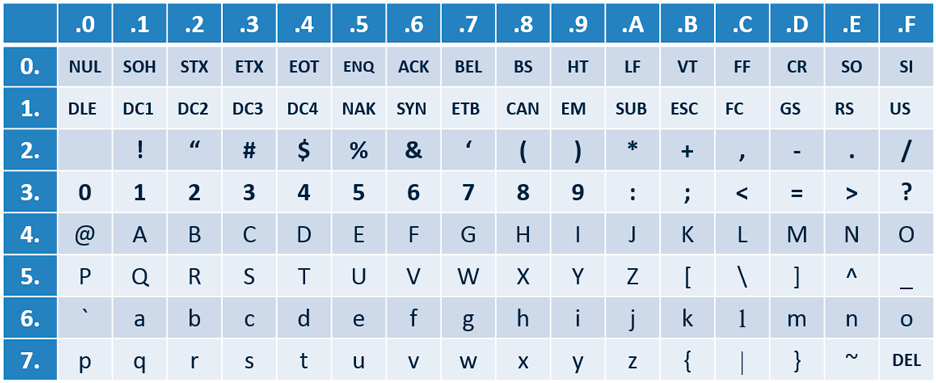
Таблица 1. Кодировка ASCII
В таблице 1 код ASCII представлен в свернутой шестнадцатеричной форме. Если развернуть в двоичную форму код превращается в семиразрядные двоичные числа (например, код 0D16 (CR) означает возврат каретки (переход к началу строки)).
В кодовой таблице ASCII соблюдается алфавитная последовательность кодировки прописных и строчных букв. Это свойство имеет важное значение для программной обработки символьной информации.
Изначально в стандарте ASCII использовался семиразрядный двоичный код. Всего можно было закодировать 27 = 128 символов. Затем, код ASCII расширили за счет добавления 8-го бита (28 = 256 символов). Первая половина восьмиразрядной кодировки совпадает с ASCII, а во второй, получившей название кодовой страницы (CP – code page), - содержатся представления символов национальных алфавитов и некоторых других знаков. Для русского языка в разных операционных системах используются свои кодовые страницы, например, Windows - CP1251, MS DOS – CP866.
Однобайтные кодировки имеют определенные неудобства, одно из которых недостаточно большое количество кодовых слов для использования одновременно нескольких языков. Для решения этих проблем в 1991 году был разработан шестнадцатиразрядный международный стандарт символьного кодирования Unicode, который позволяет закодировать 216 = 65536 символов.
Более поздние разработки стандарта Unicode за счет более сложной организации кода, при сохранении 16-ти разрядности, позволяют кодировать 1112064 символов. Таким образом, Unicode позволяет использовать в одном тексте символы алфавитов любых языков мира, в том числе и «мертвых».